Vor einiger Zeit war ich mit dem Problem konfrontiert, dass der Ladeprozess eines Data Warehouse sehr lange dauert. Zur Aufbereitung werden die MS SQL Integration services (SSIS) verwendet. Als Ursache wurde ein bestimmtes SSIS Paket ausgemacht. Im folgenden beschreibe ich, wie man solche Probleme umgehen kann, wenn man einen Script Task als Datenquelle nutzt.
Aufbau des bisherigen Paketes
Das Paket besteht aus nur sehr wenigen Teilen. Zunächst werden in der Ablaufsteuerung mit einem SQL Task Daten aus dem Quellsystem extrahiert. Da es sich bei dem Quellsystem um eine MySQL Datenbank auf einem anderen Server handelt, werden die Daten mit einem openquery abgerufen. Somit müssen die Daten mit einem SQL Task gelesen werden. Das Auslesen im Datenflusstask ist nicht möglich. Die gelesenen Daten werden in ein Result Set übergeben. Dieses wiederum dient als Quelle für einen Foreach Schleifencontainer. Innerhalb des Containers werden nun die einzelnen Insert Statements gegen die Zieldatenbank abgesetzt.
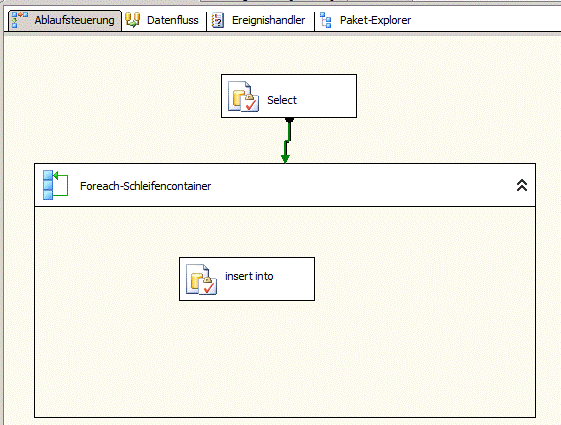
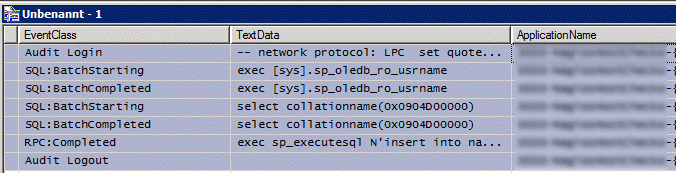
Das Insert Statement wird also für jeden Datensatz im Resultset einzeln ausgeführt. Mit dem SQL Profiler lässt sich erkennen, dass für jedes Statement eine eigene SQL Sitzung eröffnet wird. Es erfolgt also ein Login an der Datenbank, dann das Einfügen der Daten gefolgt von der Abmeldung. Dies verursacht eine enorme Laufzeit.
Aufbau des neuen Pakets mit Script Task
Um einen Bulk Insert zu erreichen, müssen die Daten an den Datenflusstask übergeben werden. Hier steht uns aber weder ein T-SQL Task, noch ein Record Set als Quelle zur Verfügung. Die gelesenen Daten können in der Ablaufsteuerung aber auch nicht in eine RAW Datei geschrieben werden, sodass die RAW Quelle ebenfalls ausscheidet.
Die Lösung ist die Verwendung des SCript Task als Datenquelle. Zunächst müssen wir auf Paketebene eine Variable definieren, die das Result Set enthält. Die Deklaration muss auf Paketebene erfolgen, damit wir sie sowohl in der Ablaufsteuerung, als auch im Datenflusstask erreichen können.
Die Daten werden wie in der ursprünglichen Lösung ausgelesen und in das Result Set übergeben. Im Datenflusstask kann nun ein Script Task erstellt werden. Als Typ muss "Quelle" ausgewählt werden.
Im anschließenden Dialog wird bei den ReadOnly Variablen das ResultSet angegeben. Im Abschnitt „Eingaben und Ausgaben“ müssen alle Spalten definiert werden, die im weiteren Datenfluss benötigt werden.
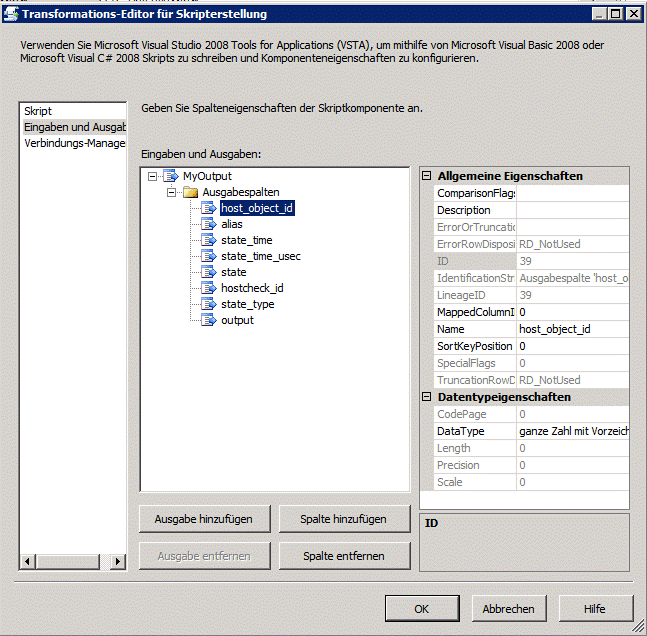
Innerhalb des Skripts wird nun in der Methode CreateNewOutputRows() jede Zeile aus dem Result Set gelesen und dem Output Puffer angefügt.
/* Microsoft SQL Server Integration Services Script Component
* Write scripts using Microsoft Visual C# 2008.
* ScriptMain is the entry point class of the script.*/
using System;
using System.Data;
using Microsoft.SqlServer.Dts.Pipeline.Wrapper;
using Microsoft.SqlServer.Dts.Runtime.Wrapper;
[Microsoft.SqlServer.Dts.Pipeline.SSISScriptComponentEntryPointAttribute]
public class ScriptMain : UserComponent
{
public override void PreExecute()
{
base.PreExecute();
/*
Add your code here for preprocessing or remove if not needed
*/
}
public override void PostExecute()
{
base.PostExecute();
/*
Add your code here for postprocessing or remove if not needed
You can set read/write variables here, for example:
Variables.MyIntVar = 100
*/
}
public override void CreateNewOutputRows()
{
System.Data.OleDb.OleDbDataAdapter adapter = new System.Data.OleDb.OleDbDataAdapter();
DataTable dt = new DataTable();
adapter.Fill(dt, this.Variables.RecordSet1);
foreach (DataRow row in dt.Rows)
{
MyOutputBuffer.AddRow();
MyOutputBuffer.alias = row["alias"].ToString();
MyOutputBuffer.hostobjectid = Convert.ToInt32(row["host_object_id"].ToString());
MyOutputBuffer.statetime = Convert.ToDateTime(row["start_time"].ToString());
MyOutputBuffer.statetimeusec = Convert.ToInt32(row["start_time_usec"].ToString());
MyOutputBuffer.state = Convert.ToInt32(row["state"].ToString());
MyOutputBuffer.statetype = Convert.ToInt32(row["state_type"].ToString());
MyOutputBuffer.output = row["output"].ToString();
MyOutputBuffer.hostcheckid = Convert.ToInt32(row["hostcheck_id"].ToString());
}
}
}
Mit dem OleDbDataAdapter kann das Result Set in eine DataTable gelesen werden. Die Zeilen der Tabelle wird dann in der Foreach Schleife dem Output Puffer übergeben. Der Name des Output Puffers setzt sich aus dem Namen der Ausgabe (siehe vorheriges Bild) und dem Wort Buffer zusammen.Im Datenflusstask kann der Inhalt des Output Puffers direkt an OLE-DB Ziels übergeben werden.
Wie im SQL Server Profiler zu sehen, wird nun ein Insert Bulk verwendet

Die Dauer des Ladeprozesses hat sich von etwa 50 Minuten auf 1,6 Minuten verkürzt.